Wissensexploration.de zeigt Vorgehensmodelle, Technologien, Ansätze und Werkzeuge, die es ermöglichen Texte zu finden, zu analysieren und in den gewonnenen (Text-)Daten nach Mustern zu suchen und betrachtet dabei das Web als Datenbasis für (verborgenes) entscheidungsrelevantes Wissen.
Dann sind Sie hier genau richtig. Sie erfahren, wie es mit einem intelligenten Web Crawler möglich ist, eine themenspezialisierte Suchmaschine (bzw. Nischensuchmaschine) zu realisieren.
Hier finden Sie Hintergrundinformationen und eine formelle Evaluation der populärsten Text Mining Anbieter (z.B. NStein, SPSS, Media Style, Megaputer, Convera uvm.)
Vor dem Hintergrund der unternehmens- und weltweit verfügbaren textuellen
Ressourcen und umfangreicher externer Quellen durch die explosionsartige Entwicklung
des World Wide Web, entsteht der Bedarf einer Texttechnologie, die „intelligente“
Schnittstellen zur Textrezeption und inhaltsorientierte Textanalysen bereitstellt,
um aufgabenrelevante Daten explorieren und kontextsensitiv aufbereiten zu
können.
Das zielgerichtete Finden und Sammeln von qualitativ hochwertigen
Webdokumenten zur Analyse und Aufbereitung mit Text Mining Technologie und
zur Wissensgewinnung im Rahmen des „Knowledge Discovery in Databases“ ist
zentrale Thematik dieser Webseite.
Ergebnis ist ein Prozess zur Wissensexploration, der einen fokussierten Web Crawler zur Selektion von
relevanten Webdokumenten, ein Text Mining System zur inhaltsanalytischen und
kontextsensitiven Aufbereitung und klassische Data Mining Methoden zur „schürfenden“
Wissensgewinnung umfasst.
Die formelle Evaluation von fokussierten Web Crawlern und
Text Mining Lösungen legt den Grundstein für ein praktisch realisierbares
Web Content Mining Projekt. weiterlesen...
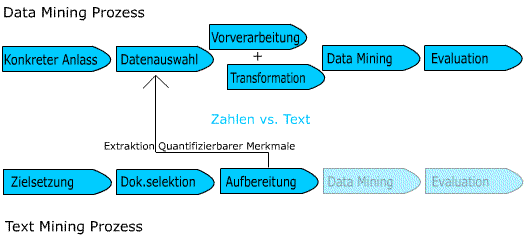
Prozess zur Wissensgewinnung (Knowledge Mining)...