Themenspezifische bzw. fokussierte Web Crawler kombinieren link-topologische und inhaltsbasierte Web Analyse Algorithmen und fokussieren ihre Suche auf einen Teilbereich des Webs (vgl. Chau und Chen, 2003, S. 58). Sie versuchen den besten Weg durch das Web zu finden. Um ein Thema bzw. eine Domäne zu beschreiben, muss Hintergrundwissen für den Crawler bereitgestellt werden, damit dieser erkennt, welche Dokumente relevant sind. Dies kann in Form von Regeln, einer Taxonomie von Dokumenten (Beispielen), oder einer formellen Beschreibung z.B. einer Ontologie erfolgen (vgl. dazu 2.5.6. Hintergrundwissen).
Der einzige Weg für den Web Crawler Webseiten und URLs zu sammeln besteht darin, wie bereits erwähnt, ausgehend von bekannten Webseiten nach Hyperlinks zu anderen (neuen) Webseiten zu suchen und diese sukzessiv abzuarbeiten (vgl. Chakrabarti, 2003, S. 18).
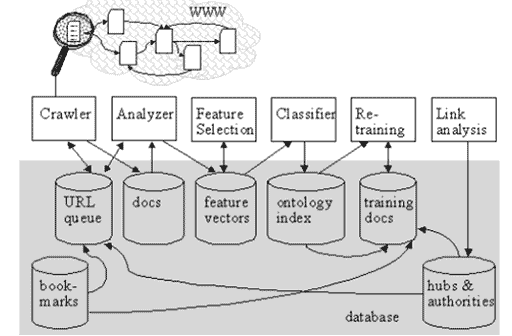
Darstellung: Architektur des Bingo! Web Crawlers; Quelle: Sizov et. al, 2004, S. 3
Fish search ist ein früher Versuch einen Crawling Prozess im Web zu fokussieren. Jede URL repräsentiert einen Fisch, dessen Überlebensfähigkeit von der Relevanz der besuchten Seite und der Geschwindigkeit des entfernten Webservers abhängt. Die Relevanz einer Seite wird durch einfaches vergleichen von Schlüsselwörtern bzw. Phrasen berechnet und beträgt entweder 1 (relevant) oder 0 (nicht relevant). Die Fischgruppe schwimmt konsequent in die Richtung relevanter Seiten; wird eine bestimmte Anzahl nicht relevanter Seiten durchschwommen, wird die Suche abgebrochen (vgl. Bra, 1994).
Eine Erweiterung des fish search Algorithmus ist der Ansatz von Hersovici et al (1998): shark search. Dabei wird die Relevanz einer Ressource auf einer Skala gewichtet und die Relevanz von benachbarten Seiten abgeschätzt. Durch die präzisere Analyse der Relevanz eines Dokuments und einer besseren Schätzung der Relevanz von benachbarten Seiten bevor diese effektiv geladen wurden, konnten in einem Experiment signifikante Verbesserungen bezüglich der gefundenen relevanten Dokumente in derselben Zeit nachgewiesen werden.
Durch die Verwendung von Hintergrundwissen in Form von Beispieldokumenten kann ein Crawling-Prozess effektiver fokussiert werden. Der Ansatz von Chakrabarti et al (1999) verwendet eine Taxonomie mit positiven und negativen Beispielen zur Klassifizierung von Webseiten. Hyperlinks auf positiv klassifizierten Webseiten werden bevorzugt abgearbeitet.
Bei Chakrabarti (1999) taucht der Begriff "focused web crawler" erstmals auf. Dabei werden die Themengebiete also nicht nur durch bestimmte Schlüsselwörter repräsentiert, sondern anhand einer Taxonomie von Beispieldokumenten klassifiziert. Die schnellere Indexierung durch die Fokussierung der Suche und die Vermeidung von irrelevanten Bereichen des Webs bringt einerseits eine Einsparung von Netzwerk- und Hardware Ressourcen mit sich, andererseits wird die Aktualisierung erleichtert und beschleunigt. Der classifier (Klassifizierer) evaluiert die Relevanz eines Dokuments in Bezug auf das Thema und ein distiller identifiziert zentrale Knoten (sog. hubs), die auf relevante Seiten verweisen.
Chakrabarti, Punera und Subramayam (2002) erweitern diesen Ansatz durch das sog. Apprentice Modul. Neben der Klassifizierung der Webseite werden auch die einzelnen URLs inhaltlich analysiert und auf ihre Relevanz hin untersucht. Dazu wird die URL, der Ankertext und der Text in der Umgebung des Verweises inhaltlich analysiert und bewertet. Der Relevanzwert sortiert die Liste der noch abzuarbeitenden Verweise entsprechend der inhaltlichen Zugehörigkeit.
Bergmark et al (2002) beschreibt eine Verbesserung bzw. Erweiterung der beschriebenen best-first Ansätze, die Tunneling-Technik: Durch die temporäre Weiterverwendung von irrelevanten Seiten, die so die Annahme eine Art Brücke zu weiteren relevanten Seiten bilden können und deshalb bis zu einem bestimmten Schwellwert in den Prozess miteinbezogen werden.
Chau und Chen (2003) verwenden einen sog. Spreading Activation Algorithmus. Dabei wird das Netz durch ein Neuronales Netz (sog. hopfield net) repräsentiert. Web Seiten (Knoten) werden parallel abgearbeitet und von mehreren Quellen bewertet, bis der Relevanzwert einen stabilen Wert erreicht und dadurch der nächste Knoten aktiviert wird (Webseite wird besucht).
Sizov et. al (2004) verwenden auch einen Klassifizierer, der die Dokumente in ein vordefiniertes Thema einer Taxonomie einordnet und zur Bestimmung der optimalen URL-Reihenfolge ein distiller verwendet. Der Klassifizierer basiert auf SVM. Beide werden durch Trainingsdaten gespeist und bestimmen die Relevanz eines Dokuments bzw. einer Ressource. Die Implementierung ist im Bingo! Crawler zu finden (vgl. Darst. 4).
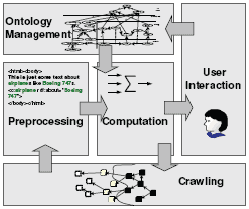 Ehrig, Hartmann und Schmitz (2004) verwenden einen ontologie-basierten Ansatz um die Relevanz von Webseiten zu berechnen (vgl. Darst. 5). Vorhandenes Hintergrundwissen über eine Domäne (eine Domänen-Ontologie) erlaubt es die Wertigkeit von Ressourcen in Bezug auf die Zugehörigkeit und Relevanz abzuschätzen, wodurch die Suche auf potentiell bedeutsamen Ressourcen fokussiert werden kann.
Ehrig, Hartmann und Schmitz (2004) verwenden einen ontologie-basierten Ansatz um die Relevanz von Webseiten zu berechnen (vgl. Darst. 5). Vorhandenes Hintergrundwissen über eine Domäne (eine Domänen-Ontologie) erlaubt es die Wertigkeit von Ressourcen in Bezug auf die Zugehörigkeit und Relevanz abzuschätzen, wodurch die Suche auf potentiell bedeutsamen Ressourcen fokussiert werden kann.
Lesen Sie weiter welche linktopologischen und inhaltsbasierten Algorithmen focusierte Crawler verwenden.