Universelle Suchmaschinen
Internet-Suchmaschinen haben ihren Ursprung in
IR Systemen. Sie erstellen einen Schlüsselwort-Index für die Dokumentbasis, um Suchanfragen über Schlüsselwörter mit einer nach Relevanz geordneten Trefferliste zu beantworten (vgl. Chakrabarti 2003, S. 45).
Um eine Dokumentbasis zu erstellen werden Programme verwendet, die eine große Anzahl an Webseiten in einen lokalen Speicher übertragen und basierend auf Schlüsselwörtern einen Index erstellen. Diese werden als Spider, Web robot, Bot oder Web Crawler bezeichnet (vgl. Chakrabarti, 2003, S. 17).
Der Web Crawler ist eine zentrale Komponente von Suchmaschinen. Er ist das Werkzeug zur Identifikation und Extraktion von Ressourcen aus dem Internet. Web Crawler unterscheiden sich je nach Anwendung bzw. Verwendung der gewonnenen Ressourcen stark in ihrer Konzeption und somit auch in ihrer Architektur (vgl. Ehrig, Hartmann und Schmitz, 2004).
Der einzige Weg für den Web Crawler Webseiten und URLs zu sammeln besteht darin, ausgehend von einer oder mehrerer seed pages (Start-URLs) nach Hyperlinks zu anderen (neuen) Webseiten zu suchen und diese sukzessive abzuarbeiten. Dies ist das fundamentale Prinzip eines Web Crawlers (vgl. Chakrabarti, 2003, S. 19).
Ausgehend von den seed pages werden alle darin enthaltenen Hyperlinks ausgelesen und sukzessiv abgearbeitet. Dieser Prozess lässt sich beliebig oft wiederholen und ermöglicht es theoretisch das gesamte Web zu indexieren. Durch das ständige Wachstum, die kontinuierliche Veränderung, verschiedene Dokumenttypen und -versionen, das Vorhandensein von dynamischen Seiten die einen Input erfordern und die Tatsache dass nicht alle Webdokumente miteinander verbunden sind, ist dies jedoch praktisch unmöglich (vgl. Lewandowski, 2005, S. 41-58).
Erster Einflussfaktor auf die Qualität einer eigenen Dokumentsammlung sind die seed pages. Werden diese sorgfältig durch Experten gewählt und repräsentieren verschiedene Bereiche des Webs kann ein großer Teil des Webs abgedeckt werden.
Ein weiterer Einflussfaktor, der auch die Aktualität eines Index beeinflusst ist die URL-Reihenfolge beim eigentlichen Crawling Prozess, also die Reihenfolge in welcher die Seiten besucht werden.
Groß angelegte Web Crawler verwenden link-topologische Ansätze, um die Webseiten global zu gewichten. Diese bauen auf citation analisis und social analisis auf und gewichten stärker verlinkte Seiten höher.
Die genaue Funktionsweise kommerzieller Web Crawler bzw. Suchmaschinen ist, wie bereits erwähnt, nicht publiziert oder liegt nur in sehr frühen Versionen vor, z.B. Google (vgl. Brin und Page, 1998).
Das Web kann als soziales Netzwerk (social network) interpretiert werden. Verweise von und zu einer Webseite zeigen nicht zufällig auf andere Inhalte, sondern verweisen auf vom Autor der Webseite ausgewählte, relevante oder interessante Inhalte. Diese Informationen können genutzt werden, um die Sammlung von Webressourcen zu fokussieren. Durch die Auswahl der am Besten verlinkten Seiten indexiert der Web Crawler wichtige Seiten zuerst; d.h. Seiten mit hohem Pagerank werden zuerst indexiert (vgl. Page et. al, 1998). Im Abschnitt 2.2.2.2 Link-basierte Web Analyse Algorithmen wird darauf näher eingegangen.
Derzeit konkurrieren drei große Anbieter im (Universal-)Suchmaschinenmarkt: Google, Yahoo! und MSN. Sie beantworten über 80 Prozent aller Suchanfragen und verkaufen ihren Index auch an Dritte (vgl. o.V., 2006). Darst. 3 veranschaulicht den Suchmaschinenmarkt.
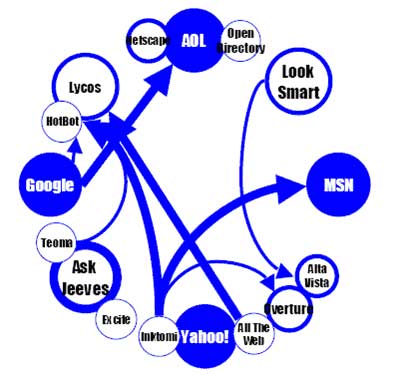
Abbildung: Suchmaschinenmarkt. Stärke der Kreise spiegelt den Marktanteil, Pfeile zeigen den Ursprung der Datenbasis der verschiedenen Anbieter; Quelle: Couvering, 2004, S. 9
Suchmaschinen bieten neben Suchmasken auf Webseiten auch Web Services an, die es erlauben, direkt mit dem Index einer Suchmaschine zu interagieren. Dadurch lassen sich Anwendungen entwickeln, die auf den Datenbestand (Index) der Suchmaschine zugreifen, ohne die Suchmaske einer Webseite zu verwenden (vgl. Müller, 2003, S. 3ff).
Deren Verwendung ist jedoch begrenzt. So sind z.B. bei der Google API maximal 1000 Abfragen pro Tag für jede Lizenz möglich. Die Datenbasis steht nur beschränkt zur Verfügung und hinzu kommt der Risikofaktor, dass diese Services in Zukunft kostenpflichtig sein könnten (vgl. http://code.google.com/apis/base/signup.html, Punkt 8). Im Bereich Web-APIs werden die Suchmaschinen APIs für Google, Yahoo und MSN beschrieben und miteinander verglichen.
Für die Initialisierung eines (fokussierten) Web Crawlers sind Suchmaschinen APIs von großem Nutzen, weil dadurch qualitativ hochwertige und gut verlinkten Seiten als Ausgangspunkt für den Crawler gefunden werden können (vgl. Sizov et. al, 2003, S. 2).
Für eine thematisch fokussierte Websuche reichen reine link-basierte Analysen nicht aus, um kontext- bzw. themenabhängig auf die Qualität einer Webseite zu schließen (vgl. Sizov et. al, 2003, S.1).
Web Crawler die (auch) anhand des Inhalts der Dokumente auf die Qualität bzw. Relevanz einer Webseite schließen, werden im Folgenden als intelligente bzw. fokussierte Web Crawler bezeichnet.
Fokussierte Web Crawler verwenden Inhalts-orientierte Algorithmen, Hintergrundwissen und Strukturinformationen, um den besten Pfad durch das Web zu finden und (für ein Thema) irrelevante Bereiche des Webs auszusparen.
Im Folgenden wird die Funktionsweise dieser intelligenten Web Crawler beschrieben.