Semantische Modelle zur Wissensrepräsentation, insbesondere Ontologien, erlauben eine formale und interpretierbare Repräsentation von Wissen für Menschen und Maschinen (vgl. Ehrig, Hartmann und Schmitz, 2004). Diese Modelle der Wissensrepräsentation werden in den verschiedensten Wissenschaftsdisziplinen eingesetzt, im Folgenden aber auf ihre Anwendung für die Informationstechnologie untersucht. Die Mächtigkeit bzw. semantische Reichhaltigkeit der Ansätze nimmt in folgender Reihenfolge zu: Glossar Taxonomie Thesaurus Topic Map Ontologie. (vgl. Darst. 11)
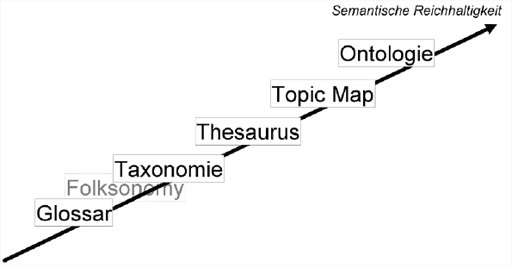
Abbildung 11: Semantische Treppe; Quelle: Blumauer, Andreas; Pellegrini, Tassilo (2006). Semantic Web und semantische Technologien. Zentrale Begriffe und Unterscheidungen. In: Pellegrini, Tassilo; Blumauer, Andreas (Hg.): Semantic Web. Wege zur vernetzten Wissensgesellschaft. Berlin: Springer Verlag, S. 9 27
Ein Glossar ist eine einfache Liste von Begriffen mit zugehöriger Erklärung. Beziehungen zu anderen Begriffen werden nicht formell festgehalten.
Die Taxonomie ist eine Hierarchie von Begriffen, die Elemente in einer Über/Unterordnung darstellt. Es lassen sich außer der hierarchischen Struktur keine Beziehungen zwischen Elementen definieren (vgl. Ullrich, Maier und Angele, 2003, S. 3). Die Lesezeichen (bookmarks) eines Web-Browser sind ein Beispiel dafür. Durch die Erstellung von Ordnern werden Kategorien gebildet in denen die Lesezeichen gespeichert werden. Beziehungen zwischen Lesezeichen einer Kategorie (z.B. ist englische Version von) können nicht ausgedrückt werden. Lesezeichen, die in mehreren Kategorien vorkommen müssen auch mehrfach gespeichert werden.
Der Thesaurus erweitert das Modell einer Taxonomie durch zwei fest definierte Relationen der Objekte untereinander: die Ähnlichkeits- und Synonymrelation. Zwei gleichbedeutende Begriffe (Synonyme) können als solche definiert werden und Objekte mit ähnlichen Eigenschaften können in Beziehung gesetzt werden (vgl. Ullrich, Maier und Angele, 2003, S.4). Beispiele: Thesaurus, Topic Map und Ontologie sind ähnlich; Data Mining und KDD sind Synonyme. In diesem Zusammenhang ist das WordNet Projekt (http://wordnet.princeton.edu/) zu erwähnen, ein sprachwissenschaftliches Universalthesaurus für die englische Sprache. Darin lassen sich neben Synonym-Beziehungen auch komplexere Relationen (z.B. Hypernyme und Redewendungen) zwischen den Begriffen modellieren.
Die Topic Map ist ein ISO Standard auf XML-Basis (http://www.isotopicmaps.org/sam/). Sie besteht aus Topics (abstrakten Dingen), Assoziationen, Scopes (Gültigkeitsbereiche für Topics) und zugeordneten Dokumenten außerhalb der Topic Map (Occurences) (vgl. Ullrich, Maier und Angele, 2003, S. 5). Assoziationen zwischen Objekten lassen sich selbst definieren.
Eine Ontologie ist in der Philosophie eine Theorie über das Wesen des Seins. Forscher in den Bereichen der Künstlichen Intelligenz und dem Web übernehmen den Terminus Ontologie in deren Jargon und verstehen darunter ein Dokument oder eine Datei die formell die Beziehungen zwischen Termen definiert. Die typische Art einer Ontologie für das Web beinhaltet eine Taxonomie und ein Set von Schlussfolgerungen und Beziehungen. (vgl. Berners-Lee, Hendler und Lassila, 2001, 2001)
Im Kontext des Semantic Web (vgl. Berners-Lee, Hendler und Lassila, 2001) und der Wissensteilung und Wissenswiederverwendung wird der Begriff häufig als eine explizite Spezifikation einer (gemeinsamen) Konzeptionalisierung definiert (vgl. Blumauer und Pellegrini, 2006, S. 12; vgl. dazu auch Ullrich, Maier und Angele, 2003, S. 6).
Durch ein mächtiges Regelwerk können Zusammenhänge zwischen Objekten der Ontologie (und anderen Ontologien) mittels Wenn-Dann Beziehungen, Zuweisungen, logischen Verknüpfungen und weiteren Funktionen ausgedrückt werden. Zudem bieten Ontologien die Möglichkeit Schema (Datenmodell) und Inhalte voneinander zu trennen (vgl. Ullrich, Maier und Angele, 2003, S. 7). Die Bandbreite der Verwendungsmöglichkeiten des Begriffs bzw. Konzepts Ontologie zeigt folgende Typisierung in Anlehnung an Blumauer und Pellegrini (2006, S. 16):
Topic Maps und Ontologien eignen sich zur Verbesserung von Suchsystemen, zur Navigation und zur Visualisierung. Ontologien erlauben zudem die Integration heterogener Datenquellen und gewährleisten Zukunftsfähigkeit, da sie die Fähigkeiten von Taxonomien, Thesauri und Topic Maps abdecken (vgl. Ullrich, Maier und Angele, 2003, S. 9-10).
Wie werden die Dokumente für das Text Mining auf- bzw. vorbereitet?