Informationsextraktion (IE) (engl. Information Extraction) ist ein pragmatischer und zielorientierter Ansatz zur Extraktion von spezifischen Informationen aus Texten. Das Feld entwickelte sich rund um die Forschungsarbeiten der Message Understanding Conferences (MUC) zwischen den Jahren 1990 und 1998 (Cunningham 2004, S.2).
Die Evaluation von IE Systemen erfolgt durch die auch in anderen Bereichen verbreiteten Maße Präzision und Vollständigkeit (vgl. Kapitel Web Information Retrieval), sowie durch das F-Maß, das beide Maße integriert (Neumann 2001, S. 450).
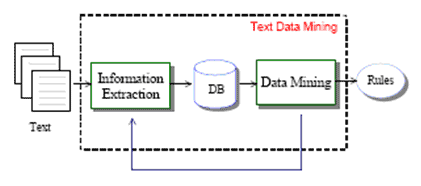
Darstellung: Ein Informationsextraktions-basiertes Text Mining Framework, Quelle: Mooney und Nahm, 2003, S. 142
Durch den Verzicht auf ein vollständiges Textverständnis bzw. eine vollständige grammatikalische Analyse erreichen derartige Systeme eine hohe Präzision und Vollständigkeit. Bereits 1998 erreichten alle Prototypen auf der der MUC-7 ein F-Maß von über 80 Prozent bei der Erkennung von sog. Named Entities (dazu gehören u.a. Personennamen, Organisationen, Orte, monetäre Beträge, sowie Datum- und Zeitangaben). Der Annotator2 Prototyp erreichte ein F-Maß von über 95 Prozent. Dies geht aus den Ergebnissen der einzelnen Prototypen hervor. (vgl. http://www.itl.nist.gov/iaui/894.02/related_projects/muc/proceedings/ne_english_score_report.html)
Deshalb wird diesem Feld besondere Aufmerksamkeit geschenkt und im nächsten Abschnitt ein Szenario für den eTourismus beschrieben, das Informationen über Spezialangebote aus Pressemitteilungen extrahiert.
Das Ergebnis eines IE-Systems ist eine strukturierte Darstellung der spezifizierten Entitäten (vgl. Cunningham, 2004, S. 14-16). In einem nächsten Schritt können Data Mining Methoden darin Muster und Regularitäten erkennen und somit latentes Wissen aus Texten gewinnen (vgl. Mooney und Nahm, 2003, S. 141ff).
Ein IE System modelliert komplexe, zusammenhängende Antwortmuster bezüglich wer, was, wem, wann, wo und eventuell warum. Die gewonnenen Daten können der Unterstützung im Text Mining Prozess dienen, um textuelle Informationen zu strukturieren und Data Mining Analysen anwendbar zu machen (vgl. Neumann 2001, S. 448).
Neumann (2001, S. 448) sieht das Ziel der IR in der Konstruktion von Systemen, die gezielt domänenspezifische Informationen in freien Texten aufspüren und strukturieren können. Dazu wird keine umfassende Analyse des gesamten Inhalts vorausgesetzt. Relevante Inhalte finden IE Systeme durch vordefinierte domänenspezifische Lexikoneinträge oder Regeln, die dem System fest vorgegeben werden.
McCallum (2005) unterteilt den IE Prozess in fünf Unteraufgaben: Segmentation findet die korrekten Start- und Endpunkte der Textschnipsel, die ein Feld in der Datenbank füllen. Classification bestimmt welcher Spalte das Textsegment angehört. Association bestimmt, welche Segmente demselben Datensatz zugeordnet werden können. Normalisation bringt die Informationen in ein einheitliches Format. Letztlich eliminiert der Deduplication Prozess redundante Informationen in der Datenbank, um doppelte Einträge zu vermeiden.
Die Spezifikation der Inhalte erfolgt durch sog. Templates (deut. Schablonen), die modellieren wer, was, wem, wann, wo und eventuell warum. Zusammen mit einer Menge von freien Textdokumenten bilden sie den Input für das System. Ausgabe ist ein instanziertes Template, das mit den Textfragmenten gefüllt worden ist (vgl. Neumann 2001, S. 448).
Die Nachteile von IE gegenüber IR sieht Cunningham (2004, S. 3) in der höheren Komplexität. IE Systeme sind schwieriger aufzubauen, wissensintensiv und benötigen mehr Rechenleistung. Vorteile sind Zeiteinsparung durch die Reduktion der Texte auf das Wesentliche und durch das einheitliche Format der Daten wird eine Weiterverarbeitung (z.B. Übersetzung oder Data Mining) stark vereinfacht bzw. erst möglich.
Der Einsatz von IE Systemen ist vielseitig: Textfilterung und Klassifikation, Einträge in Datenbanken, Unterstützung von Text Mining, Anwortextraktionssysteme und Textzusammenfassung (vgl. Neumann 2001, S. 449). Anwendungsgebiete sieht Cunningham (2004, S. 5-7) für Finanzanalysten, Marketingstrategen, PR-Arbeiter, Media Analysten etc.
Die Komplexität von freien Texten erfordert es linguistische Analysen zu bewerkstelligen. Dabei beobachtet Neumann (2001, S. 451), dass es einen Kompromiss zwischen theoretischen Ansprüchen und pragmatischen Anforderungen bei der Erstellung von IE Systemen gibt. Dies führt zu flachen Textverarbeitungsmethoden, die Komplexitätsprobleme bei der Verarbeitung der natürlichen Sprache nicht oder nur ganz pragmatisch behandeln.
IE ist also immer auf einen bestimmten Informationsbedarf ausgerichtet und durchsucht Texte systematisch nach vorab definierten Daten, Phrasen und Textsegmenten. Stehen diese Daten bereit, können Data Mining Methoden für das eigentliche Text Mining herangezogen werden.