Der zentrale Unterschied zwischen Text- und Data Mining (bzw. KDD) ist die zugrunde liegende Datenbasis (vgl. Weiss et. al, 2005, S. 2ff). Die Daten bzw. Attribute können nicht in einer Datenbank ausgewählt werden, sondern die Texte müssen vor der Auswahl in ein strukturiertes Format übertragen werden.
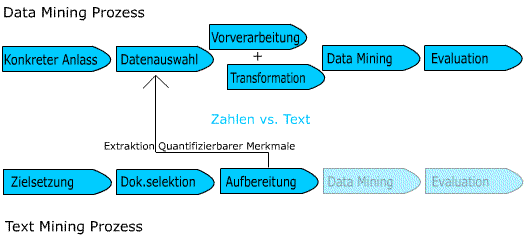
Darstellung: Vergleich von Text- und Data Mining Prozess; Quelle: eigene Darstellung
Typische Data Mining Anwendungen arbeiten auf Basis strukturierter Informationen. Die Daten werden ausgewählt, vorverarbeitet und/oder transformiert, sofern sie nicht schon angemessen extrahiert wurden (z.B. aus einer Datenbank oder einem Data Warehouse) (vgl. Weiss et. al, S. 2).
Texte können, wie bereits erwähnt, in freier, strukturierter oder halb-strukturierter Form vorliegen.
Grundlegende Unterscheidung zwischen Text und Data Mining ist also wie vom Begriff bereits suggeriert Text vs. Zahlen (vgl. Weiss et. al, 2005, S. 2). Dennoch unterscheiden sich die verwendeten Methoden grundsätzlich nicht. Um sie anwendbar zu machen müssen die Texte in eine numerische Form transformiert bzw. quantifizierbare Merkmale extrahiert werden (vgl. Spiliopoulou und Winkler, 2002, S. 118).
Weiter zum Text Mining Prozess!