Text und Hypertext Datentypen lassen sich nur schwierig mit fest definierten Größen beschreiben und lassen sich deshalb nicht mit einfachen Visualisierungstechniken darstellen.
Durch die Transformation der Texte in sog. Beschreibungsvektoren (Feature-Vektoren) werden die Texte in einem multidimensionalem Raum (Vektorraummodell) repräsentiert. Die einzelnen Vektoren repräsentieren die Dokumente durch nicht-triviale Terme und deren gewichtetes Auftreten innerhalb des Texts oder der Textsammlung (vgl. Keim, 2002, S. 32).
Im Folgenden werden drei Visualisierungstechniken vorgestellt, die sich für Text und Hypertext eignen. ThemeRiver und ThemeView visualisieren den Inhalt von Texten, der Graph im Skitter Projekt visualisiert die Struktur eines Ausschnitts des Webs (vgl. Darst. 13-15).
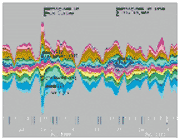
Die ThemeRiver Visualisierungstechnik visualisiert thematische Veränderungen in großen Dokumentkollektionen über einen Zeitraum. Die veränderte Breite visualisiert thematische Veränderungen (vgl. Keim, 2002, S. 33).
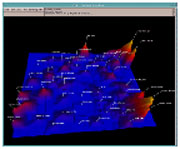
Die ThemeView Visualisierungstechnik stellt große Dokumentkollektionen als (künstliche) Landschaft dar. Berge repräsentieren häufig auftretende Themengebiete (vgl. Keim, 2002, S. 33).
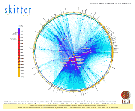 Die im Skitter Projekt (http://www.caida.org/tools/measurement/skitter) verwendete Visualisierungstechnik zeigt einen globalen Internet-Graphen. Wichtige Knoten mit einer hohen Anzahl an Verbindungen liegen weiter innen, Knoten mit einer geringen Anzahl von Verbindungen weiter außen (vgl. Keim, 2002, S. 34).
Die im Skitter Projekt (http://www.caida.org/tools/measurement/skitter) verwendete Visualisierungstechnik zeigt einen globalen Internet-Graphen. Wichtige Knoten mit einer hohen Anzahl an Verbindungen liegen weiter innen, Knoten mit einer geringen Anzahl von Verbindungen weiter außen (vgl. Keim, 2002, S. 34).
Informationsvisualisierungs-Techniken können bei der Exploration großer Textbestände bzw. beim Aufspüren interessanter Muster (z.B. Cluster und Ausreißer) helfen. Erkenntnisse über die Daten wie Muster, Strukturen und Anomalien können erkannt werden. Daraus können Hypothesen erstellt werden, die anschließend mit den Data Mining Techniken getestet werden (vgl. Filliben, 2004).
Durch Integration in ein Dokumentenmanagement-System erhält man ein leicht bedienbares und verständliches Werkzeug zur Exploration großer Textbestände (vgl. Keim, 2002, S. 38).